Önsöz: Bu yazı Tom Ryder’in “Unix as IDE” isimli yazı dizisinin Türkçe çevirisidir. Orijinalinde 7 ayrı blog girdisi olarak bulunan bu yazıyı ben tek parça halinde çevirmeyi uygun buldum. Yazının orijinaline buradan ulaşabilirsiniz.
Acemi ya da deneyimli, her programcı IDE (entegre geliştirme ortamı) konseptini sever. Entegre bir uygulamada ortak bir arayüzde kod yazmak, organize etmek, test ve debug etmek değerli bir kazanç. Bunlara ek olarak, özellikle belli bir dilde yazılım geliştirmek için tasarlanmış IDE’ler otomatik-tamamlama, syntax hatalarını gerçek zamanlı gösterme ve renklendirme gibi avantajlar da getiriyor.
Bütün bu gelişmiş araçlar her işletim sisteminde (Linux ve BSD dahil) geliştiricilere ücretsiz sunulurken, haliyle Windows Notepad ya da Nano ile kod yazmanın mantıklı bir sebebi kalmıyor.
Ancak, Unix ve modern türevlerinin sevdalıları tarafından dillendirilen, “Unix bir IDE’dir.” (Unix is an IDE) şeklinde bir ‘meme’ var. Bununla kastedilen, terminalde sahip olduğumuz araçlar zaten en modern masaüstü IDE’lerinin bir çok özelliğini (birazcık ekstra çabayla) karşılıyor. Bu konuda bir çok kişinin farklı görüşleri var, ancak Unix’i Eclipse ya da Microsoft Visual Studio bağlamında bir IDE olarak görüp görmemenizden bağımsız olarak, Bash’in ne kadar kapsamlı olabileceği sizi şaşırtabilir.
UNIX Nasıl Bir IDE Oluyor?
IDE kullanmanın en temel mantığı, uygulama geliştirirken ihtiyaç duyduğumuz bütün araçları bir araya toplaması ve bunları aynı arayüz üzerinden kullanılmasını sağlaması, bizi bu araçları koordine etme uğraşından kurtarmasıdır. Bu koordinasyon meselesi Grafik Arayüzlü araçlarda daha da öne çıkıyor, çünkü bu uygulamaların metin kopyalayıp yapıştırmak dışında paylaştıkları ortak bir arayüz yok.
Shell kullanıcıları için ise, iyi tasarlanmış her Unix aracı zaten metin ya da dosya stream leri şeklinde ortak bir arayüze sahip. Bu “Unix’te her şey bir dosyadır” felsefesi ile de açıklanabilir. Unix’te hemen hemen her şey bu konsept üzerine inşaa edilmiştir, ve bu ortak arayüz, ‘birlikte çalışabilirlik’ kuralına önem göstererek geliştirilmiş ve kullanılmış 40 yıllık süper-güçlü araçlarla birleşerek Unix’i gelişmiş bir IDE yapma konusunda epey yardımcı oluyor.
Doğru Fikir
Bu yaklaşım Unix’ci dedelere özgü bir yaklaşım da değil. Bunu iki büyük Unix metin editörü Vi ve Emacs’te de görebilirsiniz. İkisinin de hala çok aktif bir geliştirici komünitesi var ve metin düzenlemeye yönelik hemen her ihtiyaç için eklentiler geliştiriyorlar.
Ancak bu geliştirme çabaları hakkında yazılanları okurken farkediyorum ki, geliştiriciler bu editörleri kendi içinde bir IDE’ye çevirmeye çalışıyorlar. “Hiç Emacs’ten çıkmaya ihtiyaç duymamak” ya da “Hiç Vim’den çıkmaya ihtiyaç duymamak” şeklinde yazılar var. Ama bence Vim’i ya da Emacs'ı olmadığı bir şeye çevirmeye çalışmak doğru bir yaklaşım değil. Vim’in yazarı Bram Moolenaar da, “:help design-not” yazısında görebileceğiniz üzere böyle düşünüyor. Shell sadece bir Ctrl+Z uzaklıkta ve onun olgunlaşmış ve gelişmiş araç seti size iki editörün de verebileceğinden daha fazla güç ve esneklik verecektir.
Bu Yazı Hakkında
Bu yazı dizisinde bir IDE’nin 6 ana özelliği üzerinden gidip, Linux’ta bulunan standart araçları nasıl kolayca birarada kullanabileceğinizi örneklerle göstereceğim. Bu tam kapsamlı bir liste olmayacağı gibi, kullanacağım araçlar da o işi yapmanın tek yolu olmayacak.
- Dosya ve proje yonetimi —
ls, find, grep/ack, bash
- Metin editoru ve duzenleme araclari —
vim, awk, sort, column
- Derleyici ve/veya yorumlayici —
gcc, perl
- Build araclari —
make
- Debugger —
gdb, valgrind, ltrace, lsof, pmap
- Versiyon kontrol —
diff, patch, svn, git
Şunları Demeye Çalışmıyorum;
IDE’lerin kötü bir şey olduğunu düşünmüyorum, hatta harika fikirler olduklarını düşünüyorum. Zaten bu yüzden sizi Unix’in de bir IDE olarak kullanılabileceği konusunda ikna etmeye çalışıyorum. Ayrıca Unix’in her programlama işi için her zaman en iyi araç olduğunu da söylemiyorum. C, C++, Python, Perl ya da Shell geliştirme için çok daha uygun olup, Java ya da C# gibi ‘endüstri’ dilleri için o kadar da uygun değildir; özellikle GUI ağırlıklı uygulamalar geliştiriyorsanız. Size kazanmak için çok çaba sarfettiğiniz Eclipse ya da Visual Studio becerilerinizi bir kenara atmanızı da söylemiyorum. Bütün istediğim size çitin öte tarafında bizim ne yaptığımızı göstermek.
Dosyalar
Bir IDE’nin öne çıkan özelliklerinden biri, hem taşıma, ad değiştirme ya da silme gibi basit özellikleri hem de derleme ve syntax kontrolü gibi uygulama geliştirmeye yönelik fonksiyonları bulunan bir dosya yönetim sistemidir. Dosyalar üzerinde uzantıya, boyuta ya da belli kalıplara göre dosya arama da yarayışlı olabilir. Bu ilk kısımda, birçok Lınux kullanıcısının alışkın olduğu araçları, proje dosyaları üzerinde çalışmak için kullanacağız.
Dosyaları Listeleme
ls muhtemelen bir dizinin içeriğini görüntülemek için kullanacağımız ilk komuttur. Bir çok admin tüm dosya ve dizinleri göstermek için -a ve daha detaylı bilgi almak için -l parametrelerine de aşinadır.
ls için bir kaç parametre daha var ki; bunlar özellikle programlama yaparken kullanışlı olabilir;
-t — Dosyaları son modifiye tarihine göre, en yeni ilk önce gelecek şekilde listele. Bu özellikle dosya sayısı çok olan klasörlerde, en son değişen dosyaları görmek istediğimizde ise yarar, muhtemelen -l parametresi ile daha kullanışlı olur, head ya da sed 10q ile pipe’lanabilir. -r opsiyonunu ekleyerek listeyi tersine çevirip en eskileri de görebiliriz.-X — Dosyaları uzantılarına göre grupla; dizinde farklı uzantılı dosyalar varken yarayışlı olur, örneğin bir C projesinde header ve kaynak dosyalarını gruplamak için.-v — Dosya isimlerinde 1.0.1 1.1.0 gibi versiyon numaraları varsa bunları dikkate alarak sırala-S — Dosya boyutuna göre sırala.-R — Dosyaları ve alt klasördeki dosyaları recursive olarak sırala. -l yapıp less ile pipe’lanıp sayfa sayfa gezilebilir.
ls komutunun çıktısı da basitçe metin olduğu için, mesela bu çıktıyı vim’e pipe’layıp her dosya için açıklama yazıp bunu bir README ye ekleyebiliriz ya da bir envanter dosya olarak kullanabiliriz.
$ ls -XR | vim -
İlerleyen kısımlarda göreceğiz ki bu tarz şeyler make ile otomatize de edilebilir.
Dosya Bulma
Sadece find yazarak tüm dosyaların listesini alabiliriz, ama tabi bunu sort'a pipe’layarak alfabetik sıralatmak iyi bir fikir:
$ find | sort
.
./Makefile
./README
./build
./client.c
./client.h
./common.h
./project.c
./server.c
./server.h
./tests
./tests/suite1.pl
./tests/suite2.pl
./tests/suite3.pl
./tests/suite4.pl
ls -l tipi listeleme istiyorsak find’a action opsiyonu olarak -ls i de verebiliriz.
$ find -ls | sort -k 11
1155096 4 drwxr-xr-x 4 nuriye_baci nuriye_baci 4096 Feb 10 09:37 .
1155152 4 drwxr-xr-x 2 nuriye_baci nuriye_baci 4096 Feb 10 09:17 ./build
1155155 4 -rw-r--r-- 1 nuriye_baci nuriye_baci 2290 Jan 11 07:21 ./client.c
1155157 4 -rw-r--r-- 1 nuriye_baci nuriye_baci 1871 Jan 11 16:41 ./client.h
1155159 32 -rw-r--r-- 1 nuriye_baci nuriye_baci 30390 Jan 10 15:29 ./common.h
1155153 24 -rw-r--r-- 1 nuriye_baci nuriye_baci 21170 Jan 11 05:43 ./Makefile
1155154 16 -rw-r--r-- 1 nuriye_baci nuriye_baci 13966 Jan 14 07:39 ./project.c
1155080 28 -rw-r--r-- 1 nuriye_baci nuriye_baci 25840 Jan 15 22:28 ./README
1155156 32 -rw-r--r-- 1 nuriye_baci nuriye_baci 31124 Jan 11 02:34 ./server.c
1155158 4 -rw-r--r-- 1 nuriye_baci nuriye_baci 3599 Jan 16 05:27 ./server.h
1155160 4 drwxr-xr-x 2 nuriye_baci nuriye_baci 4096 Feb 10 09:29 ./tests
1155161 4 -rw-r--r-- 1 nuriye_baci nuriye_baci 288 Jan 13 03:04 ./tests/suite1.pl
1155162 4 -rw-r--r-- 1 nuriye_baci nuriye_baci 1792 Jan 13 10:06 ./tests/suite2.pl
1155163 4 -rw-r--r-- 1 nuriye_baci nuriye_baci 112 Jan 9 23:42 ./tests/suite3.pl
1155164 4 -rw-r--r-- 1 nuriye_baci nuriye_baci 144 Jan 15 02:10 ./tests/suite4.pl
Tabi bu durumda sort'a -k parametresini kullanarak 11. sütüna göre arama yapmasını söylememiz de gerekli.
find'in kendine has gelişmiş bir filtreleme syntax’i var. Aşağıdaki örnekler, belli dosyaları bulmak isterken uygulayabileceğimiz filtrelerden en kullanışlı olanları:
find -name '*.c' — shell-tarzı bir kalıpla dosyaları bul. -name yerine -iname kullanarak küçük-büyük karakter ayrımı yapmadan arar.find -path '*test*' – shell-tarzı bir kalıpla dosya yolunda bu ifade geçen dosyaları bul. -ipath kullanarak büyük küçük ayrımı yapmamasını sağlarız.find -mtime -5 — Son 5 gün içinde düzenlenen dosyaları bul. +5 yapıp en son 5 gün önce düzenlenmiş dosyaları da bulabiliriz.find -newer server.c — server.c den daha yeni dosyaları bul.find -type d — Sadece dizinleri bul. type -f dosyaları, type -l sembolik lınkleri bul.
Bu arada bunların hepsi birbiriyle birleştirilebilir. Örneğin son 2 gün içinde değiştirilmiş c dosyalarını bulmak için:
$ find -name '*.c' -mtime -2
Default olarak, find sonuçları standart output a liste olarak yazar. Ancak bunun yerine yapabileceği başka aksiyonlar da var:
-
-ls — ls -l tarzı listele, yukarıda yaptığımız gibi
-
-delete — eşleşen dosyaları sil
-
-exec — Her dosya üzerinde belli bir komut çalıştır, {} yerine dosya ismi gelecek şekilde ve \; ile komutu bitirerek, örneğin:
$ find -name '*.pl' -exec perl -c {} \;
Bütün dosyaları tek bir çağırmada işleme koymak istiyorsak komutu bitirmek için + karakteri de kullanabiliriz. Ben mesela find kullanarak bir dosya listesi üretip, onu vim’e verip dikey bölünmüş vim ekranlarında birden fazla dosya düzenlemeyi çok sık yapıyorum.
$ find -name '*.c' -exec vim {} +
Bu yazının önceki versiyonları find’in sonuçlarıyla xargs kullanmayı öneriyordu. Çoğunlukla buna gerek olmayacak, ayrıca -exec ya da while read -r döngüsüyle boşluk içeren dosya isimleri üzerinde çalışmak daha kolay.
Dosya Arama
Meta bilgilerine göre dosya aramak kullanışlı bir özellik olsa da daha çok içeriğine göre dosya bulmaya ihtiyaç duyuyoruz. Burada grep -R oldukça işimize yarıyor. Aşağıdaki komut içinde bulunduğumuz klasörde alt klasörler de dahil olmak üzere dosya içeriğinde arama yapıyor;
$ grep -FR bişeyler .
grep default olarak büyük-küçük harf duyarlı arama yapıyor, -i opsiyonuyla bunu engelleyelim
$ grep -iR bişeyler .
-l opsiyonuyla eşleşmelerin kendisini göstermeden sadece dosyaları listeleyebiliriz.
$ grep -lR bişeyler .
Yukarıdaki komutun çıktısını kullanan bir betik ya da batch job yazıyorsak dosya isimlerinde geçen boşluk ya da diğer özel karakterleri kaçırmamak için aşağıdaki gibi bir while döngüsü yapabiliriz.
grep -lR bişeyler | while IFS= read -r file; do
head "$file"
done
Projemizde versiyon kontrol kullanıyorsak, bunlar genelde .svn ya da .git gibi dizinler açıp meta bilgilerini orada saklarlar. grep’in -v opsiyonuyla buradaki dosyaları kolayca eşleşmelerden çıkarabiliriz.
$ grep -R bişeyler . | grep -vF .svn
grep’in bazı versiyonlarında --exclude ve --exclude-dir opsiyonları da var, iki kere grep yapmak yerine bunlar varsa daha temiz olur.
Bütün bunların yanında, grep’e popüler bir alternatif var: ack. ack bu tarz şeyleri bizim için en baştan eliyor. Aynı zamanda Perl uyumlu düzenli ifadeler (PCRE, çoğu hacker’in favorisi) kullanmamıza izin veriyor. Grep her zaman emrimize amade; ancak imkan varsa ack’i de kurmanızı tavsiye ederim; çünkü kod üzerinde çalışırken ise yarayacak bir çok özelliği var ve bir perl scripti olduğu için de kurması çok basit.
Unix püristleri klasik grep varken başka bir şeyin telaffuzundan dahi hoşlanmayabilirler, ama bence Unix felsefesi, yeni problemleri çözmek için aynı felsefeyi paylaşarak geliştirilmiş yeni araçlar varken klasik araçlarda ısrarcı olmayı gerektirmiyor.
file bize dosyanın uzantısına, header bilgilerine ve bir-iki başka ipucuna daha bakarak dosyanın turu hakkında tek satırlık bir özet verir. find ile beraber kullanıldığında aşina olmadığımız bir klasöre güzel bir ilk bakış olabilir:
$ find -exec file {} \;
.: directory
./hanoi: Perl script, ASCII text executable
./.hanoi.swp: Vim swap file, version 7.3
./factorial: Perl script, ASCII text executable
./bits.c: C source, ASCII text
./bits: ELF 32-bit LSB executable, Intel 80386, version ...
Dosya Eşleşme
Bu kısmın son ipucu olarak Bash’te shell expansion hakkında bilgi edinmemizde fayda var.
Yukarıdakilerin tümünü birleştirdiğimizde, UNIX shell’i programlama projelerinde gayet güçlü bir dosya yönetim aracı olarak kullanılabiliyor.
Düzenleme
Metin editörü her programcının temel aracıdır. Bu yüzden olsa gerek programcılar arasında editör seçimi hakkında biraz da makaraya dayalı bağnaz bir tartışma süregider. Unix de felsefik olarak birbirinden çok farklı ancak güç olarak birbirine yakın iki editör olan Vi ve Emacs (ve modern versiyonları GNU Emacs ve Vim) ile en güçlü bağı bulunan işletim sistemidir.
Kendim de koyu bir Vim’ci olarak, burada Vim’in programlama için olmazsa olmaz özellikleri, bilhassa da Vim’in içerisinden çağrılan ve editörün fonksiyonelliğini artıran Linux shell araçları üzerinde duracağım. Burada üzerinde duracağımız araçlardan bazıları Emacs’e de uyarlanabilir olacak, ancak Nano gibi görece daha güçsüz editörler için kuvvetle muhtemel olmayacak.
Vim’in programcılar için sunduğu araç seti çok geniş; bu nedenle burada çok genel bir inceleme yapacağız, ancak yine de epey uzun olacak. Esas ve temel şeylere odaklanıp en çok işe yaradığını düşündüğüm şeylere yer vereceğim, ve gerekli yerlerde konuyu daha geniş anlatan makalelere linkler vermeye çalışacağım. Vim’in :help komutu özellikle yeni başlayanlar için şaşırtıcı derecede yardımcı olabilir, bu da aklımızda olsun.
Dosya Tipini Belirleme
Vim standart olarak dosya türünü belirleyerek syntax renklendirme yapar. Size de istediğiniz dildeki dosyalar için indent (içerden yazma) opsiyonunu belirlememize olanak sağlar. Bu muhtemelen .vimrc dosyasında yapacağımız ilk değişiklik olmalı:
if has("autocmd")
filetype on
filetype indent on
filetype plugin ön
endif
Syntax Renklendirme
16-renkli bir terminalde bile çalışıyor olsak, aşağıdaki satırı eğer zaten yoksa .vimrc dosyamıza ekleyelim:
syntax on
Default 16-renkli terminaldeki renk şeması çok şık değil, ama iş görüyor ve bir çok dil için syntax tanımlama dosyaları mevcut. Muazzam sayıda renk şeması var ve herhangi birini kendimize uydurmak ya da baştan yazmak da zor değil. 256-renkli terminal kullanırsak daha fazla opsiyonumuz oluyor. İyi syntax renklendirme dosyaları bize syntax hatalarını dikkat çeken bir kırmızı arkaplanla gösterirler.
Satır Numaraları
Satır numaralarını göstermek için:
set number
Vim 7.3 ve üzerine sahipseniz bunu da bir deneyin derim, baştan başlayıp sırayla satır numarası vermek yerine üzerinde bulunduğunuz satıra göre üstten ve alttan sıra veriyor:
set relativenumber
Vim ctags aracının çıktısını çok iyi kullanır. Bu sayede herhangi bir tanımlayıcının (identifier) kullanıldığı yerleri aynı dosyada olmasa da hızlıca taramamızı ya da herhangi bir kullanımından direkt deklare edildiği yere zıplamamızı sağlar. Büyük C projeleri için bu ciddi zaman kazanımı sağlar, aynı zamanda Vim’in popüler IDE’lerdeki benzer özelliğe en iyi cevabıdır.
Bir çok popüler dildeki projeler için, kök dizininde :!ctags -R komutunu çalıştırıp, tags dosyasını oluşturabiliriz. Bu dosya projedeki bütün tanımlamaları ve kullanıldıkları yerleri bilgisini içerir. Bu sayede aşağıdaki gibi bir arama yapabiliriz:
:tag birClass
ya da :tag __construct gibi bir komutla bir PHP projesindeki tüm construct metodlarını bulabiliriz.
:tn ve :tp komutları bizi bir önceki ve bir sonraki kullanıma götürür. Standart olarak gelen tags fonksiyonelliği zaten muhtemelen ihtiyaç duyabileceğimiz kadarını veriyor, ama tag list penceresi gibi özellikler için popüler Taglist eklentisini deneyebilirsiniz. Tim Pope’un Unimpaired eklentisi de işe yarar eşleştirmeler (mapping) sağlıyor.
Harici Programlar Çağırma
Vim açıkken başka bir program çalıştırmanın 2 ana yolu var:
- :! — Vim konteksi içinde komut çalıştırmak, özellikle komutun çıktısını dosya içeriğine aktarmak istediğimizde
- :shell — Vim’e sub-process olarak bir shell açar. Etkileşimli komutlar için ideal.
Üçüncü bir yöntem daha var, ama üzerinde pek durmayacağız; Conque gibi eklentilerle Vim buffer’i içinde terminalı emülate etmek. Bunu şahsen denedim ve kullanışsız buldum. :help design-not makalesinden:
Vim bir shell ya da işletim sistemi değildir. Vim’in içinden shell çalıştıramaz ya da bir debugger’i kontrol etmek için kullanamazsınız. Tam tersi, Vim’i bir IDE’nin içinden ya da shell’den erişerek tamamlayıcı bir öğe gibi kullanmalısınız.
Lint Programları ve Syntax Denetleyicileri
Harici bir program kullanarak syntax’i denetlemek ya da derleme işlemini yapmak, editörün içinden :! komutlarıyla yapmak için uygun işlemler. Diyelim ki bir Perl dosyası üzerinde çalışıyoruz, syntax’te problem var mı görmek için bunu yapabiliriz:
:!perl -c %
/home/tom/project/test.pl syntax OK
Press Enter or type command to continue
%sembolü şu an açık olan dosya için kısayol. Bunu çalıştırınca komut satırının altına çıktısı varsa geliyor, Enter yapıp Vi’ye geri dönüyoruz. Bunu sık sık yapmak istiyorsak .vimrc dosyasında :PerlLint gibi bir komut hatta kısayol tanımlayabiliriz.
command PerlLint !perl -c %
nnoremap <leader>l :PerlLint<CR>
Bir çok programlama dili için bunu yapmanın daha da iyi bir yolu var. Vim’in quickfix özelliğinden yararlanmak. Dosya uzantısı için uygun bir makerpg tanımlayıp, Vim’in quicklist’te kullanabileceği bir çıktı veren bir modül yükleyip hata formatı için tanımlama ekleyerek:
:set makeprg=perl\ -c\ -MVi::QuickFix\ %
:set errorformat+=%m\ at\ %f\ line\ %l\.
:set errorformat+=%m\ at\ %f\ line\ %l
Öncelikle CPAN aracılığıyla bu modülü ya da Debian paketi libvi-quickfix-perl kurmamız gerekebilir. Bu olduktan sonra, dosyayı kaydedip make yazıp syntax hatası bulunursa, quickfix penceresini :copen komutuyla açıp hataları inceleyebilir ve :cn ve :cp komutlarıyla da bir önceki ve sonraki hatalar arasında gezinebiliriz.
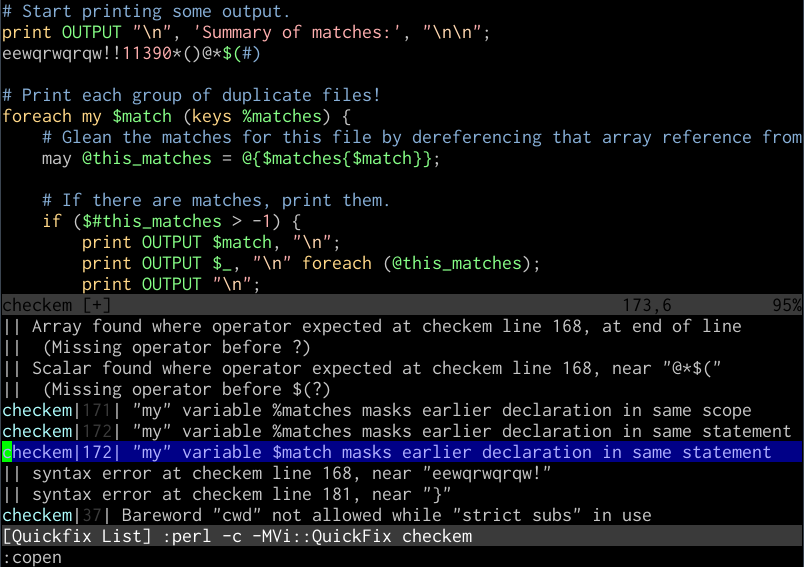 Bir Perl dosyasında Vim quickfix penceresini kullanmak
Bir Perl dosyasında Vim quickfix penceresini kullanmak
Bu gcc'nin ya da diğer bir çok derleyicinin syntax denetleyicisinin çıktısı için de iş görür. PHP gibi web odaklı diller ya da JSLint ile Javascript için de mümkün. Ayrıca Syntastic adında bir eklenti de benzer bir iş yapıyor.
Başka Komutların Çıktısını Okuma
:r! komutunu kullanarak harici komut çalıştırıp çıktısını doğrudan buffer’a yapıştırabiliriz. Örneğin ls komutuyla gelen çıktıyı direkt açık olan dosyaya yazabiliriz:
:r!ls
Tabii ki bu sadece komutlar için geçerli değil, sadece :r kullanarak başka dosyaları da içeri alabiliriz:
:r ~/.ssh/id_rsa.pub
:r ~/dev/perl/boilerplate/copyright.pl
İlave Komutlar Kullanarak Filtreleme
Bunu ilave komutlarla buffer’daki metni filtreleyip komutun çıktısıyla değiştirmek için de kullanabiliriz. Vim’in block modu sütun yapısındaki veriyle çalışmak için çok uygun ama column, cut, sort ya da awk gibi komutlarla işimizi daha hızlı da halledebiliriz.
Örneğin, bütün metni ikinci sütundaki veriye göre tersten sıralamak için:
:%!sort -k2 -r
Seçilmiş bir metindeki eşleşen satırlarda sadece üçüncü sütundaki veriyi gösterebiliriz:
:'<,'>!awk '/vim/ {print $3}'
1’den 10. satıra kadarki yazıları tablo gibi düzgün sütunlara bölmek için:
:1,10!column -t
Vim’de tüm filtreler ve komutlar bu şekilde kullanılabilir. Bu basit birlikte çalışabilirlik özelliği sayesinde editörün yetenekleri kat be kat artmış oluyor. Vim buffer'ını bir metin stream’ine çevirerek bütün klasik Unix araçları tarafından işlenebilmesini sağlıyor.
Dahili Alternatifler
Sıralama ya da arama gibi çok temel operasyonlar için Vim’in kendi içinde :sort ve :grep şeklinde metodları var. Eğer Vim’i Windows’ta kullanmak zorunda kaldıysanız ve shell araçlarına erişiminiz yoksa aklınızda bulunsun.
Farkları Görme (Diff’leme)
Vim’in bir diffleme modu var: vimdiff. Bu bize bir dosyanın farklı versiyonları arasındaki farkları görme imkanı verdiği gibi :diffput ve :diffget gibi komutlarla üç yönlü birleştirme (merge) de yapabiliyoruz. vimdiff’i direkt komut satırından aşağıdaki gibi çağırabiliriz:
$ vimdiff file-v1.c file-v2.c
Bir .vimrc dosyasını Vim’de diff’leme
Versiyon kontrolü
Vim içerisinden direkt versiyon kontrol metodlarını çağırabiliriz ki zaten bu da işimizi fazlasıyla görür. Yine % sembolünün buffer’da şu an açık olan dosya için kısayol olduğunu hatırlamakta fayda var:
:!svn status
:!svn add %
:!git commit -a
Tim Pope tarafından geliştirilen Fugitive, Vim’de Git kullanan herkese tavsiye edeceğim bir eklenti. Bu yazının 7. kısmında Unix’te versiyon kontrolü konusunu daha kapsamlı ele alacağız.
Fark
Görsel tabanlı IDE kullanmaya alışmış bir çok programcının Vim’i oyuncak ya da tarihi eser gibi düşünmesinin sebebi, onu sadece sunucudaki dosyaları düzenlemek için bir araç olarak görmelerinden ileri gelir. Vim’in kendi içindeki özellikleri ve bu özelliklerin Unix-dostu diğer araçlarla birleştirilebilirliği onun bazen en deneyimli kullanıcıları bile şaşırtacak güçte bir metin düzenleme aracı olmasını sağlar.
Derleme
Unix platformunda kod derleme ve yorumlama (interpreting) için çok sayıda araç var, ve her birinin kendine özgü kullanım şekilleri olsa da konsept olarak çoğunlukla aynı adımları içeriyor. Burada C kodu derlemek için gcc ve yorumlanan bir dil örneği olması açısından perl den kısaca bahsedeceğim.
GCC
GCC GPL lisanslıyla dağıtılan, çoğunlukla C ve C++ ile çalışmak için popüler, çok olgun bir derleyici koleksiyonudur. Özgür lisansı ve neredeyse her Unix türevi sistemde hazır bulunması onu oldukça popüler yapmış olsa da LLVM ve Clang gibi modern alternatifleri de vardır.
GNU Derleyici Koleksiyonu’nun önyüz binary’lerinin her biri işleme (parsing), derleme ve linkleme gibi spesifik işler gerçekleştirir. Bu sayede GCC’den basit bir komutla direkt C kodundan çalışabilir bir dosya alabildiğimiz gibi, ihtiyacımız olduğunda bu adımlardan herhangi birine müdahale ederek o aşamadaki ayarları değiştirebiliriz de.
Burada make dosyalarının kullanımından bahsetmeyeceğim, ama kuvvetle muhtemel, birden fazla dosyası olan her C projesinde Makefile kullanmak isteyeceksiniz. Buna Build otomasyon araçları kısmında değineceğim.
Derleme ve Toplama (Assemble)
C kodundan object kodunu aşağıdaki gibi alabiliriz:
$ gcc -c example.c -o example.o
example.c’nin geçerli bir C programı olduğunu varsayarsak, bu aynı dizinde example.o adında linklenmemiş bir object dosyası oluşturacak, ya da oluşturamıyorsa nedenini söyleyecek. objdump aracıyla object dosyasının içeriğini inceleyebiliriz.
$ objdump -D example.o
Veya -S parametresini kullanarak assembly kodunu doğrudan bir dosyaya da yazdırabiliriz.
$ gcc -c -S example.c -o example.s
Şöyle bir komutla aldığımız bu tarz bir assembly çıktısı, özellikle kaynak koduyla beraber ekrana bastırıldığında öğretici ya da en azından ilginç olabilir:
$ gcc -c -g -Wa,-a,-ad example.c > example.lst
Preprocessor (Ön İşleyici)
C ön işleyicisi cpp, kabaca header dosyalarını içermek ve makrolar tanımlamak için kullanılır. gcc derleme işleminin normal bir parçasıdır, ama doğrudan kendisini çağırarak ürettiği C kodunu da görebiliriz:
$ cpp example.c
Bu komut, include lar ve alakalı makrolar uygulanmış şekilde derlenecek olan tam kaynak kodunu ekrana basar.
Objeleri Linkleme
Bir ya da daha fazla obje binary’lere aşağıdaki gibi linklenebilir:
$ gcc example.o -o example
Bu örnekte, GCC’nin tüm yaptığı ld'yi (GNU linkleyicisi) çağırmak. Bu komut example isminde çalıştırılabilir bir binary üretir.
Derleme, Toplama (Assemble) ve Linkleme
Yukarıdakilerin tamamı tek seferde aşağıdaki gibi yapılabilir:
$ gcc example.c -o example
Bu biraz daha basit, ama objeleri tek tek derlemek gereksiz kod derlemeyi azalttığı için performans avantajı sağlıyor. Buna bir sonraki kısımda değineceğim.
Dahil Etme (include) ve Linkleme
C kaynak ve header dosyaları -I parametresiyle özellikle belirterek de dahil edilebilir:
$ gcc -I/usr/include/somelib.h example.c -o example
Benzer şekilde, eğer kodumuzun /lib ya da /usr/lib gibi ortak dizinlerden herhangi birindeki bir derlenmiş sistem kütüphanesi ile linklenmesi gerekiyorsa, bu -l parametresiyle yapılabilir:
$ gcc -lncurses example.c -o example
Derleme sürecimizde çokça include ve linkleme varsa, bunları ortam değişkenlerinde tanımlamak iyi olur:
$ export CFLAGS=-I/usr/ınclude/somelib.h
$ export CLIBS=-lncurses
$ gcc $CFLAGS $CLIBS example.c -o example
Bir çok projede benzer olan bu adım da Makefileın kullanım alanlarından biridir.
Derleme Planı
gcc tam olarak ne yapıyor detaylı görmek istiyorsak -v opsiyonuyla derleme işlemini nasıl tamamlamayı planladığını standart error’a yazmasını sağlayabiliriz:
$ gcc -v -c example.c -o example.o
-### opsiyonunu kullanarak obje dosyalarını ve linklenmiş binary’leri oluşturacakmış gibi yapıp oluşturmamasını, sadece yapacaklarını ekrana basmasını sağlayabiliriz:
$ gcc -### -c example.c -o example.o
Bu da gcc bizim için neleri basitleştiriyor, aslında tam olarak ne oluyor görmek için kullanılabilir.
Daha Ayrıntılı Hata Kontrolü
-Wall ve/veya -pedantic opsiyonlarını ekleyerek bizi hataya sebebiyet verebilecek şeyler hakkında uyarmasını sağlayabiliriz:
$ gcc -Wall -pedantic -c example.c -o example.o
Bunu Makefile ya da Vim’de makeprg tanımlamalarımıza ekleyebiliriz, bir önceki kısımda bahsettiğimiz quickfix penceresi ile uyumlu çalışır. Uyarılar bu şekilde daha kapsamlı olacağı için daha okunaklı, uyumlu ve daha az hataya açık kod yazmamıza yardımcı olur.
Derleme Süresinin Profilini Çıkarma
gcc ye -time opsiyonunu eklersek her adımın ne kadar sürdüğünü çıktıda gösterir:
$ gcc -time -c example.c -o example.o
Optimizasyon
gcc ye optimizasyon opsiyonları vererek daha verimli obje dosyaları ve linklenmiş binary üretmeyi denemesini sağlayabiliriz. Yapabileceği iyileştirmeler var mı diye bakıp, bunları uygular. Tabii bunun karşılığında derleme süresi uzar. Ben şahsen -O2 nin son kullanıcıya gidecek (production) olan kod için genellikle uygun bir değer olduğunu tecrübe ettim:
Tabii ki her Bash komutu gibi, bunlar da Vim içinden çağrılabilir:
:!gcc % -o example
Yorumlayıcılar
Unix türevlerinde yorumlanmış koda yaklaşım çok farklıdır. Buradaki örneklerde Perl kullanacağım, ama bu prensiplerin çoğu PHP ya da Python’a da uyarlanabilir.
Satır İçi
Aşağıda direkt komut satırından bir satır Perl kodu çalıştırmanın üç farklı yöntemini görüyoruz. Üçünün de yaptığı şey aynı: “Hello World” ve satır sonu yazdırmak. Birincisi en temizi ve muhtemelen en standart yöntem. İkincisi heredoc stringi kullanıyor. Üçüncüsü de kodu Perl’e pipe’liyor.
$ perl -e 'print "Hello world.\n";'
$ perl <<<'print "Hello world.\n";'
$ echo 'print "Hello world.\n";' | perl
Tabii ki kodu bir dosyada tutup, doğrudan onu çağırmak daha normal:
$ perl hello.pl
Her iki örnekte de c parametresini ekleyerek kodu çalıştırmadan syntax kontrolü yapabiliriz:
$ perl -c hello.pl
Bu betik dosyasını bir binary gibi kullanmak, direkt çağırabilmek için, ilk satıra shebang dediğimiz, dosyanın hangi yorumlayıcıyla çalıştırılacağını belirleyen özel bir metin ekleriz:
#!/usr/bin/env perl
print "Hello, world.\n";
Betik dosyasını yazdıktan sonra chmod ile execute (çalıştırma) yetkisini de eklememiz gerekli. Bu esnada dosyayı uzantısını silecek şekilde yeniden adlandırmak da iyi bir pratik çünkü bu artık bir binary şekline gelmiş oluyor.
$ mv hello{.pl,}
$ chmod +x hello
Bundan sonra derlenmiş bir binary gibi doğrudan çalıştırılabilir:
$ ./hello
Bu çok kullanışlı bir metoddur; ki modern Linux sistemlerinde useradd komutunun önünde duran adduser gibi bir çok ortak araç Perl hatta Python’la yazılmıştır.
Bir sonraki kısımda projelerin build işlemini tanımlamak ve bu işleri otomatize etmek için make nasıl kullanılır bunu göreceğiz, aynı zamanda aynı fikre yeni bir yaklaşım olan Ruby’nin rake'ine de bir selam çakacağız.
Alakalı Yazılar
Build Etme
Projeleri derlemek çok karmaşık ve tekrar tekrar yapılan bir iş olabileceği için IDE’ler build işlemini basitleştirmek hatta tamamen otomatize etmek için imkanlar sunarlar. Unix ve türevleri bunu Makefile dediğimiz standart bir formatı olan tarif dosyaları ile sağlarlar. Makefile lar kaynak kod ve obje dosyalarından çalıştırılabilir dosyalar üretirler, ve değişiklikleri dikkate alıp tekrar build etmesi gerek olmayan dosyaları eleyerek zaman israfını önlerler.
make genellikle yazılım derleme için kullanılsa ve bunun için de çokça kısayol sağlasa da, aslında belli bir grup dosyadan başka bir grup dosya elde etmek istediğimiz hemen her durumda kullanılabilir. Örnek olarak bir web sitesi deployment esnasında sitede kullanılan resimleri web için optimize edilmiş resimlere çevirmek verilebilir. Ya da kaynak kodundan html dosyalar üretebiliriz, istek anında üretmek yerine. Yazılım derlemeye bu esnek bakış Ruby’deki rake gibi her türlü dosyayı üretme, yükleme gibi genel işleri otomatize eden araçlarla popüler olmuştur.
Bir Makefile in Anatomisi
Bir Makefile in genel yapısı bir değişken listesi, bir hedef (target) listesi ve bunları sağlayan kaynak ve/veya obje dosyaları şeklindedir. Hedefler binary olmak zorunda değil, oluşturulan dosyaları kullanmak üzerine aksiyonlar da olabilir. Örnek olarak build edilmiş dosyaları sisteme entegre etmek için kullanılan install ya da bu dosyaları kaynak dizininden temizleyen clean verilebilir.
Hedeflerin bu şekilde esnek olabilmesi, makein herhangi bir yazılımı paketleme, son kullanıcıya hazır hale getirme sürecinde olabilecek her türlü işi otomatize edebilmesini sağlar. Sadece derleme değil, test çalıştırma make test, dokümantasyon kaynak dosyalarını istenen formatlara çevirme, ya da kodu production ortamına aktarma, bir web sitesini git push ya da benzer metodlarla upload etme gibi örnekler verilebilir.
Basit bir C projesi için Makefile dosyası aşağıdaki gibi olabilir:
all: example
example: main.o example.o library.o
gcc main.o example.o library.o -o example
main.o: main.c
gcc -c main.c -o main.o
example.o: example.c
gcc -c example.c -o example.o
library.o: library.c
gcc -c library.c -o library.o
clean:
rm *.o example
install: example
cp example /usr/bin
Yukarıdaki örnek bu proje için en optimal Makefile değil, ama sadece make yazarak kaynaktan binary oluşmasını ve bunu kurmasını sağlamak için yeterli. Formata baktığımızda her hedef ardından gelen komutu çalıştırmak için gereken bağımlılıkları listeliyor. Tanımlamalar belli bir sıra içinde olmak zorunda değil, make bağımlılıkların hepsini okuyarak alakalı komutları uygun bir sırada çağırır.
Yukarıdaki örnek basitleştirilebilir. Örneğin bir obje dosyası aynı isimli tek bir C dosyasından oluşturuluyorsa bunu hedef olarak belirtmeye gerek yok, make kendisi bunu anlayıp yapacaktır. Bir iyileştirme de çokça kullanılan isimleri değişken olarak tanımlamak olabilir. Bu sayede farklı bir derleyici kullanmak istersek ya da bir şeylerin ismi değişirse, bir tek değişiklik ile bunu sağlama avantajımız olur. Bu söylediklerimize göre toparlanmış Makefile dosyamız:
CC = gcc
OBJECTS = main.o example.o library.o
BINARY = example
all: example
example: $(OBJECTS)
$(CC) $(OBJECTS) -o $(BİNARY)
clean:
rm -f $(BİNARY) $(OBJECTS)
install: example
cp $(BİNARY) /usr/bin
makein Genel Amaçlı Kullanıma Daha Fazla Örnek
İnsanlar genelde makein kod derleme ve kurma dışında bir kullanım alanı olduğunu düşünmez. Ama bu noktada, build olayına sadece derlemek olarak değil de daha genel anlamda bakmak yararlı olacaktır. Mesela bir PHP projesinin yayına alınması da aynı prensipte bir iştir. Elimizde kaynaklar, build işlemi yaparak ulaşmak istediğimiz hedefler var.
Tabii ki PHP dosyalarının derlenmeye ihtiyacı yok, ama bazı web kaynaklarının var. Web geliştiricilerin aşina olduğu resim dosyalarının web için optimize edilmesi örnek verilebilir.
Bu proje için 4 adet 64x64 piksel boyutlarında ikon dosyası olduğunu varsayalım. Kaynak kodda bunlar vektörel SVG formatında bulunuyor. Deploy esnasında ise daha küçük .png formatında resimler üretiyoruz. icons diye bir hedef tanımlayıp, bağımlılıklarını belirleyip çalıştırılması gereken komutları yazarız:
icons: create.png read.png update.png delete.png
create.png: create.svg
convert create.svg create.raw.png && \
pngcrush create.raw.png create.png
read.png: read.svg
convert read.svg read.raw.png && \
pngcrush read.raw.png read.png
update.png: update.svg
convert update.svg update.raw.png && \
pngcrush update.raw.png update.png
delete.png: delete.svg
convert delete.svg delete.raw.png && \
pngcrush delete.raw.png delete.png
Yukarıdaki gibi bir Makefile hazırladıktan sonra, make icons yazarak 4 ikon için de ImageMagick’in convert metodunu kullanarak SVG’den PNG’ye çevirmeyi, pngcrush ile de png’leri optimize edip upload’a hazır hale getirmeyi sağlamış oluruz.
Benzer bir yaklaşım çeşitli formatlarda yardım dosyaları oluşturmak için de kullanılabilir. Örneğin Markdown kaynağından HTML dosyaları oluşturmak için:
docs: README.html credits.html
README.html: README.md
markdown README.md > README.html
credits.html: credits.md
markdown credits.md > credits.html
Ve son olarak belki de siteyi git push web gibi bir komutla deploy etmek, ama ancak ikonlar ve dökümanlar hazır olduktan sonra:
deploy: icons docs
git push web
Belli bir uzantıyı başka bir uzantıya çevirmek için daha genel bir tarif için .SUFFIXES direktifini kullanabiliriz. $< kaynak dosyayı, $* uzantı olmadan dosya ismini, ve $@ de hedefi gösteren semboller olarak kullanılır. .svg den .png ye bir .SUFFIXES direktifi aşağıdaki gibi olabilir:
icons: create.png read.png update.png delete.png
.SUFFIXES: .svg .png
.svg.png:
convert $< $*.raw.png && \
pngcrush $*.raw.png $@
Makefile Oluşturma Araçları
GNU Autotools araçları içerisinde daha geniş yazılım projeleri için configure betikleri ve make dosyaları oluşturan araçlar var; autoconf ve automake. Bu iki aracın kullanımı, çok geniş kod tabanları için farklı işletim sistemleri ile uyumlu ve derlenebilir olduğundan emin olmak için gereken adımları otomatize etmeyi ve diğer türlü elle yazılması gerekecek olan uzun Makefile dosyalarını oluşturmaya yarıyor.
Bu süreç başlı başına bir yazı dizisi olabilecek kadar kompleks ve bu inceleme yazısının kapsamı dışında.
Alakalı Yazılar
*Compiling in $HOME
Hata Ayıklama (Debug)
Linux’un bir programda beklenmedik durumlar oluştuğunda problemi teşhis etmek için kullanabileceğimiz çeşitli araçları vardır. gdb (GNU Debugger) ve daha az bilinen Perl debugger, IDE’lerde programın çalışma anında durumunu gözlemlemek için kırılma noktaları koymaya alışkın programcılara tanıdık gelecektir. Bir programın sistemle nasıl etkileştiği ve kaynakları nasıl kullandığını daha detaylı gözlemleyebileceğimiz araçlar da mevcut.
gdb ile Hata Ayıklama
gdb nin kullanımı Eclipse ya da Visual Studio gibi modern IDE’lerdeki dahili hata ayıklayıcılara epey benzer. Az önce derlediğimiz bir programda hata ayıklama yapacaksak, derlemeyi debugging sembolleriyle birlikte yapmak mantıklı olur. Bunun için gcc'ye -g opsiyonunu ekleriz. -Wall (Warning all) opsiyonunu da eklersek diğer türlü gözümüzden kaçabilecek hataları da görmüş oluruz:
$ gcc -g -Wall example.c -o example
gdb kullanmanın klasik yolu şöyledir; C ya da C++ ile derlenmiş bir program çalışmakta iken biz shell’de program hata verip çökeceği noktaya doğru giderken programın durumunu adım adım ilerleterek görürüz.
$ gdb example
...
Reading symbols from /home/tom/example...done.
(gdb)
gdb istemcisine geçtikten sonra run yazıp programı başlatabiliriz. Burada hataların sebebini, kaynak dosya ve satır numarası gibi bilgileri edinebiliriz. Yukarıdaki gibi debugging sembolleriyle derleme yapıp sonra gdb ye geçebiliyorsak, herhangi bir hatanın sebebini bulmak çok daha kolay olur.
(gdb) run
Starting program: /home/tom/gdb/example
Program received signal SIGSEGV, Segmentation fault.
0x000000000040072e in main () at example.c:43
43 printf("%d\n", *segfault);
gdb shell’indeyken, program bir hata nedeniyle sonlanırsa backtrace yazarak çağrılan fonksiyonu ve programın çökme sebebiyle ilişkili olabilecek parametrelerin o anki değerleri nelerdi görebiliriz.
(gdb) backtrace
#0 0x000000000040072e in main () at example.c:43
gdb de break satır_numarası ya da break fonksiyon_ismi yazarak o noktaya gelince programın durmasını sağlayabiliriz:
(gdb) break 42
Breakpoint 1 at 0x400722: file example.c, line 42.
(gdb) break malloc
Breakpoint 1 at 0x4004c0
(gdb) run
Starting program: /home/tom/gdb/example
Breakpoint 1, 0x00007ffff7df2310 in malloc () from /lib64/ld-linux-x86-64.so.2
Bundan sonra da adım adım ilerlemek için step komutunu kullanabiliriz. Her seferinde tekrar step yazmamıza gerek yok, Enter’a basarak aynı komutu tekrar çalıştırmasını sağlayabiliriz. Bu sadece step için değil tüm gdb komutları için geçerli.
(gdb) step
Single stepping until exit from function _start,
which has no line number information.
0x00007ffff7a74db0 in __libc_start_main () from /lib/x86_64-linux-gnu/libc.so.6
Halihazırda çalışmakta olan bir process’in process ID’sini bulup gdb’yi monte etmemiz de mümkün:
$ pgrep example
1524
$ gdb -p 1524
Bu şekilde bir kullanım özellikle beklenmedik şekilde uzun süren işlemlerin çıktılarını yönlendirmek için yarayışlı olabilir.
valgrind ile Hata Ayıklama
Çok daha yeni bir hata ayıklama aracı olan Valgrind de benzer şekilde kullanılabilir. Bu programın gerçekleştirebileceği bir çok farklı hata ayıklama metodu var, en işe yararlardan birisi tampon taşması (buffer overflow) gibi genel bellek hatalarını bulmakta kullanabileceğimiz Memcheck tır.
$ valgrind --leak-check=yes ./example
==29557== Memcheck, a memory error detector
==29557== Copyright (C) 2002-2011, and GNU GPL'd, by Julian Seward et al.
==29557== Using Valgrind-3.7.0 and LibVEX; rerun with -h for copyright info
==29557== Command: ./example
==29557==
==29557== Invalid read of size 1
==29557== at 0x40072E: main (example.c:43)
==29557== Address 0x0 is not stack'd, malloc'd or (recently) free'd
==29557==
...
gdb ve valgrind bir programın çalışmasının eksiksiz bir incelemesi için beraber kullanılabilir.
Zed Shaw tarafından yazılan Learn C the Hard Way kitabında kasıtlı olarak bozuk yazılmış bir program üzerinde orta düzeyde Vagrand kullanımı içeren çok güzel bir kısım var.
ltrace ile Sistem ve Kütüphane Çağrılarının İzini Sürme
strace ve ltrace sistem çağrılarını ve kütüphane çağrılarını izleyebilmek için geliştirilmiş araçlardır.
ltrace e sadece istediğimiz programı parametre olarak verip bu program bitene kadar yaptığı sistem ve kütüphane çağrılarını listeleyebiliriz:
$ ltrace ./example
__libc_start_main(0x4006ad, 1, 0x7fff9d7e5838, 0x400770, 0x400760
srand(4, 0x7fff9d7e5838, 0x7fff9d7e5848, 0, 0x7ff3aebde320) = 0
malloc(24) = 0x01070010
rand(0, 0x1070020, 0, 0x1070000, 0x7ff3aebdee60) = 0x754e7ddd
malloc(24) = 0x01070030
rand(0x7ff3aebdee60, 24, 0, 0x1070020, 0x7ff3aebdeec8) = 0x11265233
malloc(24) = 0x01070050
rand(0x7ff3aebdee60, 24, 0, 0x1070040, 0x7ff3aebdeec8) = 0x18799942
malloc(24) = 0x01070070
rand(0x7ff3aebdee60, 24, 0, 0x1070060, 0x7ff3aebdeec8) = 0x214a541e
malloc(24) = 0x01070090
rand(0x7ff3aebdee60, 24, 0, 0x1070080, 0x7ff3aebdeec8) = 0x1b6d90f3
malloc(24) = 0x010700b0
rand(0x7ff3aebdee60, 24, 0, 0x10700a0, 0x7ff3aebdeec8) = 0x2e19c419
malloc(24) = 0x010700d0
rand(0x7ff3aebdee60, 24, 0, 0x10700c0, 0x7ff3aebdeec8) = 0x35bc1a99
malloc(24) = 0x010700f0
rand(0x7ff3aebdee60, 24, 0, 0x10700e0, 0x7ff3aebdeec8) = 0x53b8d61b
malloc(24) = 0x01070110
rand(0x7ff3aebdee60, 24, 0, 0x1070100, 0x7ff3aebdeec8) = 0x18e0f924
malloc(24) = 0x01070130
rand(0x7ff3aebdee60, 24, 0, 0x1070120, 0x7ff3aebdeec8) = 0x27a51979
--- SIGSEGV (Segmentation fault) ---
+++ killed by SIGSEGV +++
Zaten çalışmakta olan bir programa da uygulayabiliriz:
$ pgrep example
5138
$ ltrace -p 5138
ltrace in çıktısı genelde ekrana sığamayacak kadar uzun olur, o yüzden -o opsiyonunu kullanarak çıktıyı bir dosyaya kaydetmek daha mantıklı olabilir:
$ ltrace -o example.ltrace ./example
Sonra bu dosyayı ltrace çıktısı için syntax renklendirme özelliği olan Vim editöründe açabiliriz:
 Vim’de ltrace çıktısı
Vim’de ltrace çıktısı
ltracein yanlış linkleme ya da chroot ortamında bazı gerekli kaynakların eksik olduğu için ortaya çıkan problemleri bulmak için çok kullanışlı olduğunu tecrübe ettim. Çünkü çıktısında dinamik linkleme esnasında yaptığı kütüphane aramalarını, /etc dizinindeki konfigürasyon dosyalarını açışını ve /dev/random ya da /dev/zero gibi cihazların kullanımını da dökümante ediyor.
lsof ile Açık Dosyaları Takip Etme
Çalışmakta olan bir process’in hangi dosyaları, stream’leri ya da aygıtları kullanmakta olduğunu görmek istiyorsak bunu lsof ile yapabiliriz:
$ pgrep example
5051
$ lsof -p 5051
Örnek olarak, benim bilgisayarımda çalışan apache2 process’inin ilk bir kaç satırı:
# lsof -p 30779
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
apache2 30779 root cwd DIR 8,1 4096 2 /
apache2 30779 root rtd DIR 8,1 4096 2 /
apache2 30779 root txt REG 8,1 485384 990111 /usr/lib/apache2/mpm-prefork/apache2
apache2 30779 root DEL REG 8,1 1087891 /lib/x86_64-linux-gnu/libgcc_s.so.1
apache2 30779 root mem REG 8,1 35216 1079715 /usr/lib/php5/20090626/pdo_mysql.so
...
Bunu yapmanın diğer bir yolu, ilgili process’in /proc dizinindeki girdisini okumaktır:
$ ls -l /proc/30779/fd
Bu da dosya kilitleriyle ilgili karmaşık durumları çözmek ya da bir process ihtiyacı olmayan dosyaları açıkta tutuyor mu görmek için çok kullanışlı bir yöntem.
pmap ile Bellek Paylaşımını Görme
Son hata ayıklama ipucumuz pmap. pmap ile bir process’in bellek kullanımını görebiliriz:
# pmap 30779
30779: /usr/sbin/apache2 -k start
00007fdb3883e000 84K r-x-- /lib/x86_64-linux-gnu/libgcc_s.so.1 (deleted)
00007fdb38853000 2048K ----- /lib/x86_64-linux-gnu/libgcc_s.so.1 (deleted)
00007fdb38a53000 4K rw--- /lib/x86_64-linux-gnu/libgcc_s.so.1 (deleted)
00007fdb38a54000 4K ----- [ anon ]
00007fdb38a55000 8192K rw--- [ anon ]
00007fdb392e5000 28K r-x-- /usr/lib/php5/20090626/pdo_mysql.so
00007fdb392ec000 2048K ----- /usr/lib/php5/20090626/pdo_mysql.so
00007fdb394ec000 4K r---- /usr/lib/php5/20090626/pdo_mysql.so
00007fdb394ed000 4K rw--- /usr/lib/php5/20090626/pdo_mysql.so
...
total 152520K
Bu bize çalışmakta olan bir process, paylaşılan bellekte olanlar da dahil olmak üzere hangi kütüphaneleri kullandığını gösterir. En alt satırda verilen toplam (total) biraz yanıltıcı olabilir; çünkü paylaşılan kütüphaneleri tek kullanan process bizim process olmayabilir. Paylaşılan kütüphaneler de işin içine girince bir process’in tam olarak ne kadar bellek kullandığını anlamak göründüğünden biraz daha karmaşık olabilir.
Revizyonlar
Versiyon kontrolü artık profesyonel yazılım geliştirmenin olmazsa olmaz bir parçası olarak görülmekte. Masaüstü IDE’ler de bunu benimseyip endüstri standardı haline gelmiş versiyon kontrol sistemlerine dahili destek sunmuş durumdalar. Modern versiyon kontrol sistemleri diff ve patch gibi programlardan gelen Unix konseptlerinden evrilmiş olsalar da hala sayısı azımsanmayacak sayıda insan bir versiyon kontrol sistemi kullanmanın en iyi yolunun shell istemcisi olduğunu savunur.
Bu son kısımda, diff ve patch gibi ilk versiyon kontrol araçlarından başlayarak yaygın açık kaynaklı versiyon kontrol sistemlerinin evrimi üzerinden geçeceğim.
diff, patch, ve RCS
Versiyon kontrol sistemleri için temel konseptlerden biri, bir ya da daha fazla dosyada yapılmış değişiklikleri hem bilgisayar hem insan tarafından okunabilecek bir formatta içeren birleşik diff diye tanımlayabileceğimiz bir dosyadır. diff komutu ilk olarak Douglas McIlroy tarafından 1974’te Unix’in 5. sürümü için yayınlanmıştır ve bugün modern sistemlerde kullanılan en eski komutlardan biridir.
Bir dosyanın iki farklı versiyonunu karşılaştırıp farkları bu en ortak ve birlikte çalışılabilir format diyebileceğimiz birleşik diff formatında almak için aşağıdaki syntaxi kullanabiliriz:
$ diff -u example.{1,2}.c
--- example.c.1 2012-02-15 20:15:37.000000000 +1300
+++ example.c.2 2012-02-15 20:15:57.000000000 +1300
@@ -1,8 +1,9 @@
#include <stdio.h>
+#include <stdlib.h>
int main (int argc, char* argv[]) { printf("Hello, world!\n");
- return 0;
+ return EXIT_SUCCESS; }
Bu örnekte, ikinci dosyaya bir header dosyası eklendiğini ve main() fonksiyonunun 0 yerine EXIT_SUCCESS döndürecek şekilde değiştirildiğini görüyoruz. diff in çıktısı aynı zamanda değiştirilen dosyanın adı ve değiştirilme tarihi gibi meta bilgileri de içeriyor; bunu da görebiliyoruz.
Geniş kod tabanları için ilkel bir versiyon kontrol formu da bu nedenle geliştiricilerin diff çıktılarını birbirleriyle paylaşmaları şeklindeydi. Bu sayede diff komutu ile aldıkları değişiklikleri patch komutunu kullanarak kendi kod tabanlarına uygulayabilirlerdi. Şu şekilde diff çıktısını bir yama dosyası olarak alabilirdik:
$ diff -u example.{1,2}.c > example.patch
Sonra bu yamayı, dosyanın eski bir versiyonuna sahip bir geliştiriciye gönderebilirdik. O da bu yamayı şu şekilde uygulayabilirdi:
$ patch example.1.c < example.patch
Bir yama farklı klasörlerdeki birden fazla dosyadan diff içeriği bulundurabilir. Bu sayede kod ağacına yapılan tüm değişiklikleri tek yamada uygulayabilirdik.
Bir dosyanın geçmişini kendisiyle beraber tutmak için Source Code Control System ve bunun yerine geçen Revision Control System geliştirildi. RCS dosyaları kilitleme (locking) özelliğini getirdi. Bir dosya checkout edildiğinde başka birisi tarafından düzenlenmesine izin vermiyordu. Bu özellik gelişmiş versiyon kontrol sistemlerinde benzer başka konseptlerin geliştirilmesine önayak oldu.
RCS, kullanımının çok basit olması avantajını koruyor. Var olan bir dosyayı versiyon kontrolüne almak için ci <dosya_ismi> yazmamız yeterli. Sonrasında bizden dosya için bir tanım girmemizi isteyecek:
$ ci example.c
example.c,v <-- example.c
enter description, terminated with single '.' or end of file:
NOTE: This is NOT the log message!
>> example file
>> .
initial revision: 1.1
done
Bu işlem aynı dizinde example.c,v adında, değişiklikleri kayıt edecek bir dosya yaratacak. Dosyada değişiklik yapmak için, dosyayı checkout (co) ediyoruz, istediğimiz değişiklikleri yapıp tekrar checkin (ci) ediyoruz.
$ co -l example.c
example.c,v --> example.c
revision 1.1 (locked)
done
$ vim example.c
$ ci -u example.c
example.c,v <-- example.c
new revision: 1.2; previous revision: 1.1
enter log message, terminated with single '.' or end of file:
>> added a line
>> .
done
Sonra projenin geçmişini rlog komutu ile görebiliriz:
$ rlog example.c
RCS file: example.c,v
Working file: example.c
head: 1.2
branch:
locks: strict
access list:
symbolic names:
keyword substitution: kv
total revisions: 2; selected revisions: 2
description:
example file
----------------------------
revision 1.2
date: 2012/02/15 07:39:16; author: tom; state: Exp; lines: +1 -0
added a line
----------------------------
revision 1.1
date: 2012/02/15 07:36:23; author: tom; state: Exp;
Initial revision
=============================================================================
İki revizyon arasındaki farkları birleşik diff formatında bir yama olarak almak için rcsdiff -u komutunu kullanabiliriz:
$ rcsdiff -u -r1.1 -r1.2 ./example.c
===================================================================
RCS file: ./example.c,v
retrieving revision 1.1
retrieving revision 1.2
diff -u -r1.1 -r1.2
--- ./example.c 2012/02/15 07:36:23 1.1
+++ ./example.c 2012/02/15 07:39:16 1.2
@@ -4,6 +4,7 @@
int main (int argc, char* argv[])
{
printf("Hello, world!\n");
+ printf("Extra line!\n");
return EXIT_SUCCESS;
}
Basit yamalar artık versiyon kontrol için kullanılmıyor gibi bir ima oluşturursak bu yanlış olur. Yamalar hala hem yukarıdaki şekilde hem de merkezi ve dağınık versiyon kontrol sistemlerinde yaygın bir şekilde kullanılmaya devam etmekte.
CVS ve Subversion
Bir kod tabanına birden fazla geliştirici tarafından yapılan değişiklikleri çözümleyip koda uygulama problemi ile başa çıkmak için merkezi versiyon sistemleri geliştirildi. İlk geliştirilen Concurrent Versions System (CVS) ve daha sonra geliştirilen ve biraz daha gelişmiş bir sistem olarak Subversion olmak üzere iki yaygın kullanılan merkezi versiyon sistemi var. Bu sistemlere merkezi denmesinin sebebi, depoyu barındıran merkezi bir sunucu olması ve bu sunucudan istenen sürüm ya da zaman dilimine ait kodun alınabilmesidir. Bunlara çalışma kopyaları (working copy) ismi verilir.
Bu sistemler için temel operasyon birimi yapılan değişiklikleri içeren changeset lerdir. Bu değişiklikleri de diff formatında kullanıcıya gösterirler. İki sistem de dosyaların kendisini değil de bu changeset leri tutmak suretiyle çalışırlar.
Bu jenerasyon sistemler tarafından üretilen bir konsept dallanma (branching) idi. Branching sayesinde aynı projenin farklı örnekleri üzerinde eş zamanlı olarak çalışmak mümkündü. Daha sonra gerekli testler ve incelemeler yapıldıktan sonra bu branch ler asıl kod diyebileceğimiz ana hatta ya da trunk a taşınabilirdi. Etiketleme de (tagging) bir release esnasında kodun bulunduğu durumu işaretlemek için yine bu sistemler tarafından üretildi. Bir dosyaya yapılan değişikliklerde çakışma olduğunda el ile düzenleme yapma yani birleştirme (merge), yine bu sistemler tarafından ortaya çıkarılan diğer bir konsept.
Git ve Mercurial
Versiyon kontrol sistemlerinin bir sonraki jenerasyonu dağıtık ya da merkezi olmayan sistemler, her çalışma kopyasının projenin tüm geçmiş bilgisini de barındırması, bu nedenle de merkezi bir sunucuya ihtiyaç duymaması fikrine dayalıdır. Git ve Mercurial Unix ve türevlerinde kullanılan iki popüler sistemdir. Git’in git, Mercurial’in ise hg adında istemcileri vardır.
Bu iki sistemde de değişikliklerin alış-verişi push, pull ve merge araçlarıyla yapılır. Bu dağınık sistem çok karmaşık ama sıkıca kontrol edilen bir geliştirme ortamına olanak tanır; ki Git Linus Torvalds tarafından Linux çekirdeğini ve yapılan geliştirmeleri idare edebilecek kapasitede bir açık-kaynak sistem olması için geliştirilmişti.
Hem Git hem Mercurial, CVS ve Subversion’dan temel operasyon birimleri yönüyle ayrılır. SVN ve CVS’te bu birimler yapılan değişiklikler iken, Git ve Mercurial’da tüm dosyanın (blob) sıkıştırılmış halleridir. Bu nedenle tek bir dosyanın geçmişini ya da iki versiyonu arasındaki farkları bulmak SVN’e göre biraz daha maliyetli bir iştir. Ama git log --patch komutunun çıktısı yine de birleşik diff çıktısına çok benzer, aradaki 40 yıla rağmen:
commit c1e5559ddb09f8d02b989596b0f4100ad1aab422
Author: Tom Ryder <[email protected]>
Date: Thu Feb 2 01:14:21 2012
Changed my mind about this one.
diff --git a/vim/vimrc b/vim/vimrc index cfbe8e0..65a3143 100644
--- a/vim/vimrc
+++ b/vim/vimrc
@@ -47,10 +47,6 @@
set shiftwidth=4
set softtabstop=4
set tabstop=4
-" Heresy
-inoremap <C-a> <Home>
-inoremap <C-e> <End>
-
" History
set history=1000
Git ve Mercurial fonksiyonellikte, hatta komut listesinde ciddi benzerlik gösterirler. Hangisi tercih edilmeli konusunda da ciddi tartışmalar dönmektedir. Git için gördüğüm en iyi takdim yazısı Scott Chacon tarafından yazılan Pro Git. Mercurial için ise Joel Spolsky tarafından yazılan Hg Init.
Alakalı Yazılar
Sonuç
Bu kısım ile inceleyeceğimiz özellikler son buluyor. Profesyonel IDE’ler tarafından sunulan temel özelliklerin tamamını karşılayabilecek bu temel Linux shell araçlarının hızlı bir incelemesini yapmaya çalıştım. Bazı noktalarda bazı özellikleri açıklarken istediğim kadar detaya inmemek durumunda kaldım (çok dağıtmamak adına), ama umut ediyorum ki bu Linux ortamında geliştirme yapmaya yabancı olan okuyuculara, bütün bu özgür, olgun ve standart araçlarla beraber naçiz Linux shell’inin ne kadar kapsamlı olabileceği hakkında iyi bir fikir verecektir.